
[Optical Flow/10] FlowNet 2.0 (CVPR 2017)
This post is written by YoungJ-Baek
You can see the original Korean version at Searching Fundamental
Preface
In the previous post, we covered FlowNet, the first DL-based Optical Flow algorithm. Despite having several important contributions, FlowNet fell behind in performance compared to the traditional handcrafted approach, EpicFlow. FlowNet2.0 is a network created to improve the performance of FlowNet.
In this post, we will focus on the key differences that FlowNet2.0 has compared to the previous version, that led to performance improvement.
 FlowNet vs FlowNet2.0
FlowNet vs FlowNet2.0
Dataset
FlowNet2.0 pre-trained on the previously used Flying Chairs dataset and then further trained on the newly added FlyingThings3D (Things3D) dataset.
 FlyingThings3D Dataset
FlyingThings3D Dataset
The paper expresses that the order of presenting training data with different properties matters. As a result, the paper suggests a method of pretraining with Chairs and then fine-tuning with the more real Things3D dataset.
FlyingThings3D Dataset
Also, more training was conducted compared to FlowNet, and additional training using the ChairsSDHom dataset was also carried out to improve Small Displacement performance. More details on this will be covered at the following posts.
 ChairsSDHom Dataset
ChairsSDHom Dataset
Architecture
In the previous post, it was mentioned that FlowNet2.0 inherits everything from FlowNet. This can be understood from the network architecture. FlowNet2.0 improves performance by combining FlowNetS and FlowNetC proposed in FlowNet. Various combinations are presented in the paper, and the combination of FlowNetC + FlowNetS + FlowNetS showed the best performance.
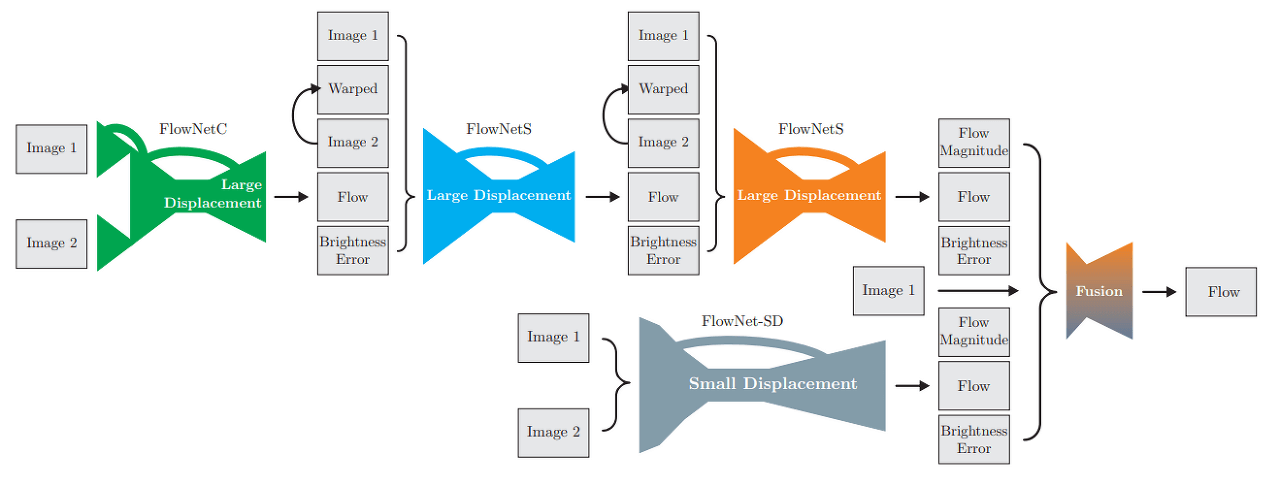 FlowNet2.0 Architecture
FlowNet2.0 Architecture
The technique of stacking networks to achieve better performance is quite common. However, FlowNet2.0 not only stopped there but also added something of its own - FlowNet-SD to address Small Displacement. This will be discussed in more detail later.
Ultimately, FlowNet2.0 acquires flow, flow magnitude, and brightness error from two models, FlowNet2-CSS-ft-sd and FlowNet2-SD. Each network corresponds to Large Displacement and Small Displacement, and the Fusion layer reflects both results to generate the final Flow Map.
FlowNet-SD
Although FlowNet was an optical flow algorithm, it had the advantage of being quite robust in the face of large displacements. However, it was surprisingly vulnerable in small displacements, making it difficult to apply in real-world problems. I have two possible explanations for this.
First, the dataset used to train FlowNet was biased toward large displacements. Deep learning is entirely dependent on the dataset, and since FlowNet used synthetic data instead of real-world data, it may have generated biased data. This seems plausible given that FlowNet-SD has somewhat addressed this issue.
Second, there are inherent limitations in the CNN structure. CNNs have an enormous computational load, which inevitably leads to the use of pooling layers. This can result in the loss of a significant amount of information as well as a decrease in resolution. This naturally leads to a similar effect to the Coarse-to-Fine technique and causes an error propagation problem. Additionally, since large movements are expressed by small pixels, there may be a significant effect of small movements being completely ignored.
Anyway, regardless of these personal opinions, FlowNet-SD first reduced the stride and made the feature map more sensitive to small changes when generating a feature map from FlowNetS. Additionally, to correspond to small displacements, it trained using ChairsSDHom dataset, which has smaller movements and follows the displacement histogram of UCF101.
Result
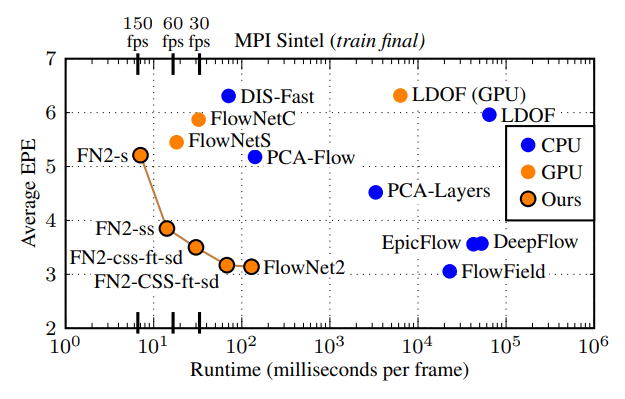 Runtime vs EPE comparison
Runtime vs EPE comparison
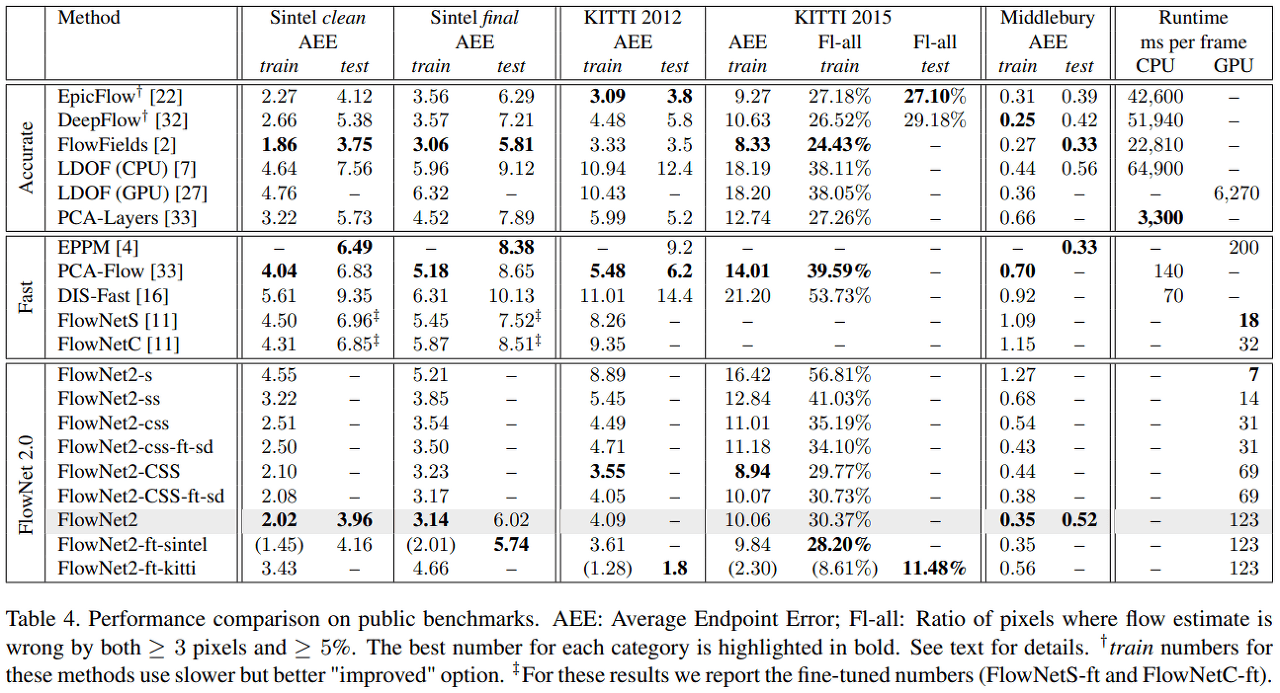 Performance comparison
Performance comparison
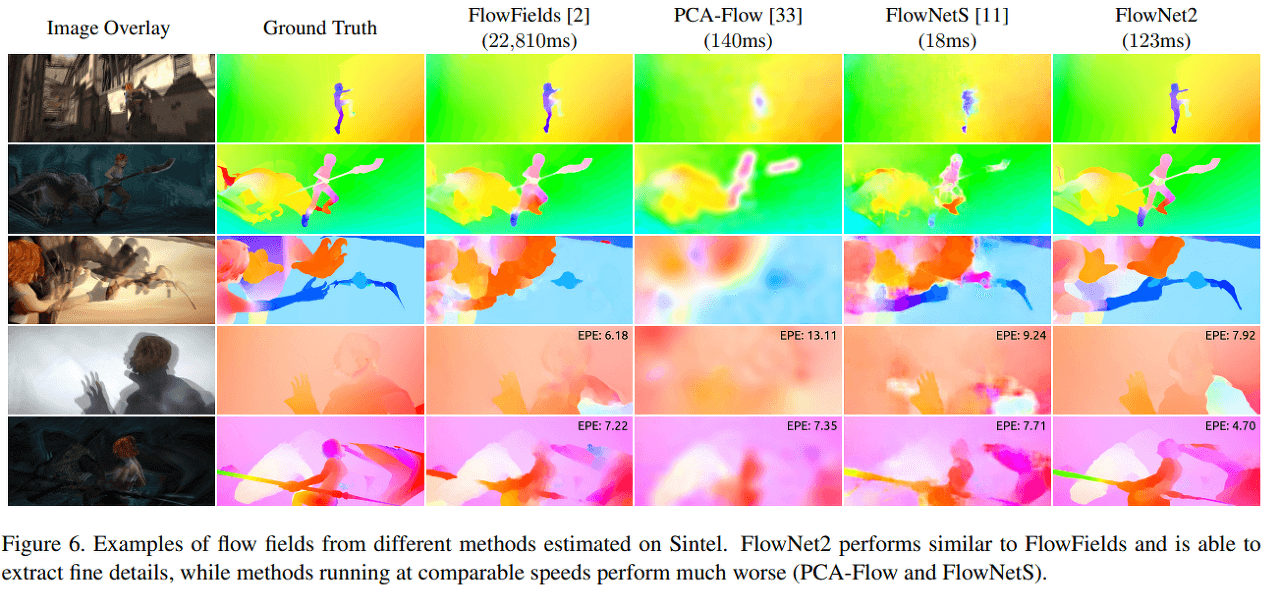 Examples of flow fields
Examples of flow fields
Leave a comment